Pearls Before SwAIne
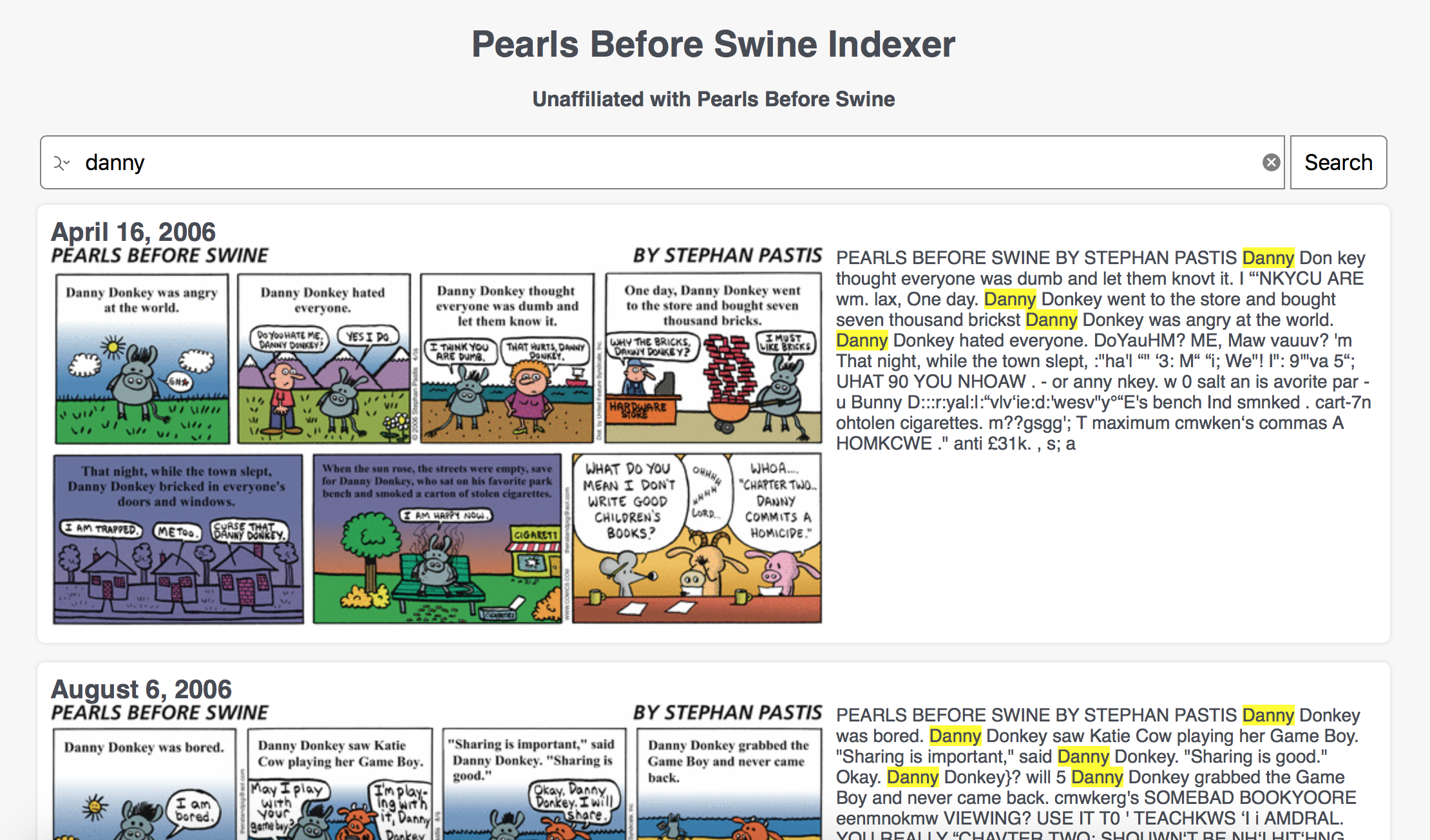
Back in 2016 I wrote some code to automatically transcribe 'Pearls Before Swine' comic strips to make them searchable. At the time, this transcription relied on Tesseract, the "state of the art" OSS OCR program. As part of that I used a segmentation algorithm based on linear whitespace to separate the original strip into boxes, and then attempted to do something similar for the bounding boxes of the text. This had a lot of problems, in part because the OCR program was not that good on the handdrawn font, in part because the dialogue boxes were inconsistent (which you can see in the image below), and in part because my code wasn't very good.
Since then OCR has had some improvements, but mostly in proprietary software, with Tesseract still leading in lists of modern recommendations despite how abysmally it performs years on. But who else to the rescue but an LLM! I'm not sure what mixture of separate OCR code, MoE, and clever tricks with visual attention are responsible for visual LLM's success at this, but the modern state of the art transcription looks a lot less like Python code and a lot more like just politely asking a black box.
Here's what the transcription attempt looked like from 2016.

And here's what it looks like using OpenAI's gpt-4o model.

All this took was submitting the image of the current comic, along with this prompt:
Please transcribe the text from this image. Don't include any details about panels and characters, and just return the full spoken text. Please don't add in unwritten quotation marks, and please add newlines between speech bubbles. Please also try to match the capitalization of the image (i.e. if the text is all uppercase, keep it in uppercase).
Another issue with the 2016 approach is that the transcription was a point-in-time scrape, which means that by now the indexer was missing nearly 8 years of strip data. To rectify this, I scraped the missing comics, and set up a cronjob to automatically scrape new ones, run them through OpenAI to get the transcript, save them to the DB so they can be searched, and post the latest one to the subreddit. I also ran the updated OCR approach across all 8,193 comics for almost 23 years, which cost $18.40, or 1 cent/5 images. If you're trying to find a specific Pearls Before Swine comic you can use the search here.
All of the code is also here on my GitHub if you're interested.