Pearls Before Swine Indexer
I moderate the subreddit /r/PearlsBeforeSwine, and there are a bunch of posts from people trying to track down a specific comic from the past. After trying to help a few people, I figured there was a better way to do it: so I built the Pearls Before Swine Indexer.
I wrote a Python script to get all of the URLs to the comics from http://gocomics.com/pearlsbeforeswine. Then I used the pytesseract library that leverages google's OCR (optical character recognition) code to get the text from each image. Finally I put all of it into a database and packaged it up with search functionality so that you can try and find the comic strip that was driving you crazy.
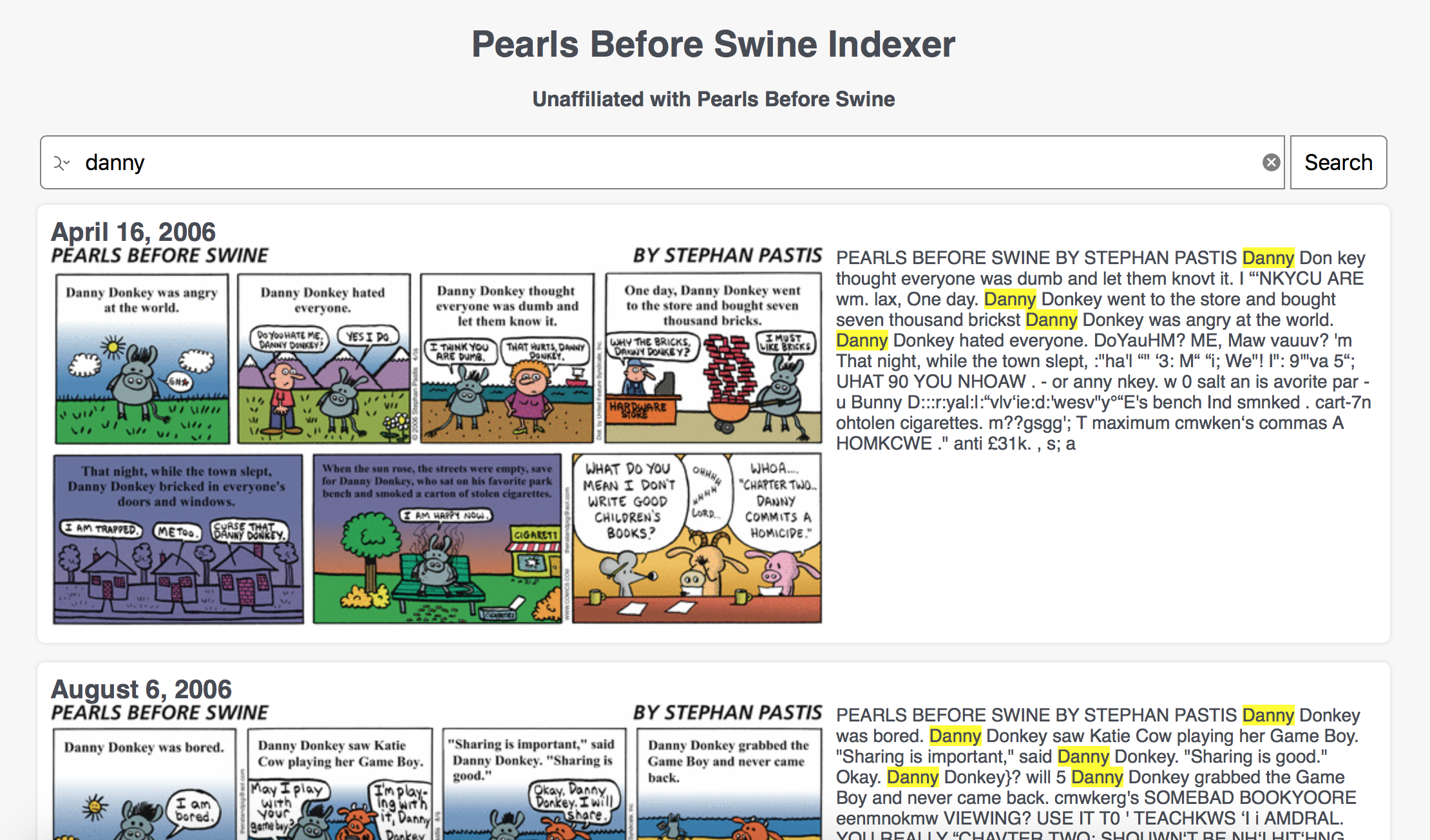
As you can see, the OCR isn't perfect, but it's roughly good enough, especially if you try a bunch of words that you remember from the strip. In this case, I searched for 'danny' to try and find all of the 'Danny the Donkey' strips, and it worked pretty well!
Overall a fun and pretty easy project, and one that will hopefully help people in the future.
Nate Williams
THANK YOU SO MUCH! This is so helpful. One comic it can't seem to find is the one about the feminese dialect being so complex it makes the navajo language look like a dick and jane primer. Currently looking for that one.